
关于使用通用Mapper
通用Mapper简单好学,能少写很多单表查询,对喜欢使用Mybatis的猿来说是一个很好的功能,值得拥有。
另外作者的文档写的已经很清楚了,所以这里就只记录一下个人在SpringBoot中是如何使用的。推荐去官方文档仔细阅读一下。
如何在项目中集成通用Mapper
简单的说。先在你的pom文件里添加依赖。
1 | <dependency> |
然后去你的属性文件里加上
1 | mapper.mappers=tk.mybatis.mapper.common.Mapper |
然后在你的入口类上加上@tk.mybatis.spring.annotation.MapperScan(baesePackages=”扫描包”),注意是@tk.mybatis.spring.annotation.MapperScan而不是@MapperScan。(如果不用这个注解需要去接口上一个一个的添加@Mappeer注解。)
在通用Mapper中,默认会将实体类中的驼峰命名方式转变为数据库中的下划线形式,例如实体类中的userName会被转变为user_name。
所以在实际使用时,如果我们的命名足够规范,实体类的名称和表名对应,实体类的属性名和表中的字段名称对应,我们只需要使用@Id注解来表明哪一个字段是主键,同时使用@KeySql(useGeneratedKeys = true)来标明具体的主键生成策略。这样就可以满足基本的使用需求了。如果想要有进一步更细化的配置,可以仔细阅读官方文档的2.1,2.2,2.3章节。
如果没有@Id<注解来表明那一个字段是主键时,当使用通用Mapper中带有ByPrimaryKesy的方法时,所有的字段将作为联合主键被使用
最后需要注意的是在DAO层的接口上,我们需要去继承一个通用Mapper提供的Mapper<实例类的class文件>接口。
Example的用法以及自定义的SQL
当做完上述这些配置,我们就已经可以在项目中使用通用Mapper了,再使用时如果想要自己去写自定义的SQL,有两种方式,一种是使用在接口上使用注解:
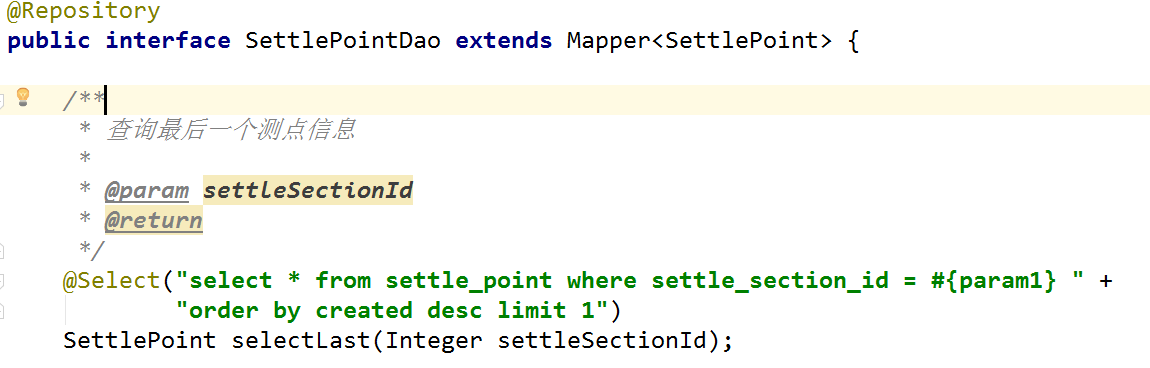
另一种就是常用的XML文件形式,可以根据自己的喜好去选择。
另外关于单表查询中想要按照的条件来查询,可以使用Example,用法有些类似于hibernate的findByExample。具体使用的方式如下:
1 | Example example = new Example(Country.class); |
生成的SQL如下:
1 | DEBUG [main] - ==> Preparing: SELECT id,countryname,countrycode FROM country WHERE ( countryname like ? ) ORDER BY id desc |